 Paper
Paper

 Citation
Citation

Abstract
Recent advancements in controllable text-to-image (T2I) diffusion models, such as Ctrl-X and FreeControl, have demonstrated robust spatial and appearance control without requiring auxiliary module training. However, these models often struggle to accurately preserve spatial structures and fail to capture fine-grained conditions related to object poses and scene layouts. To address these challenges, we propose a training-free Dual Recursive Feedback (DRF) system that properly reflects control conditions in controllable T2I models. The proposed DRF consists of appearance feedback and generation feedback that recursively refines the intermediate latents to better reflect the given appearance information and the user's intent. This dual-update mechanism guides latent representations toward reliable manifolds, effectively integrating structural and appearance attributes. Our approach enables fine-grained generation even between class-invariant structure-appearance fusion, such as transferring human motion onto a tiger's form. Extensive experiments demonstrate the efficacy of our method in producing high-quality, semantically coherent, and structurally consistent image generations.
Conceptual Visualization of Dual Recursive Feedback
Illustration of a diffusion-based generative model with latent feedback mechanisms (DRF) for controlling both appearance and generation latent in class-invariant text-to-image synthesis. The proposed method refines latent updates to achieve fine-grained control, improving results with desired structural and appearance attributes.
Method
Appearance feedback
Appearance feedback refines the appearance latent \(z_t^a\) so that the denoised estimate \(z_{0|t}^a\) converges toward a stable appearance code \(z_0^a\) extracted from the reference image. We modify the stochastic update of \(z_t^a\) and minimize a reconstruction loss between \(z_{0|t}^a\) and \(z_0^a\). This fixed-point style update suppresses appearance leakage and preserves identity even under class-invariant structure–appearance fusion.
Generation feedback
Generation feedback operates on the fused generation latent \(z_t^g\). At each recursive step, we treat the previous output \(z_{\mathrm{prev}}^g\) as another fixed point and enforce the current posterior \(z_{0|t}^g\) to stay close to it via an output-space loss. An iteration-dependent weight \(w_{\text{iter}}^{(i)}\) gradually shifts the emphasis from appearance feedback (early steps) to generation feedback (later steps), so DRF first locks in the reference identity and then improves alignment with the target structure and text prompt.
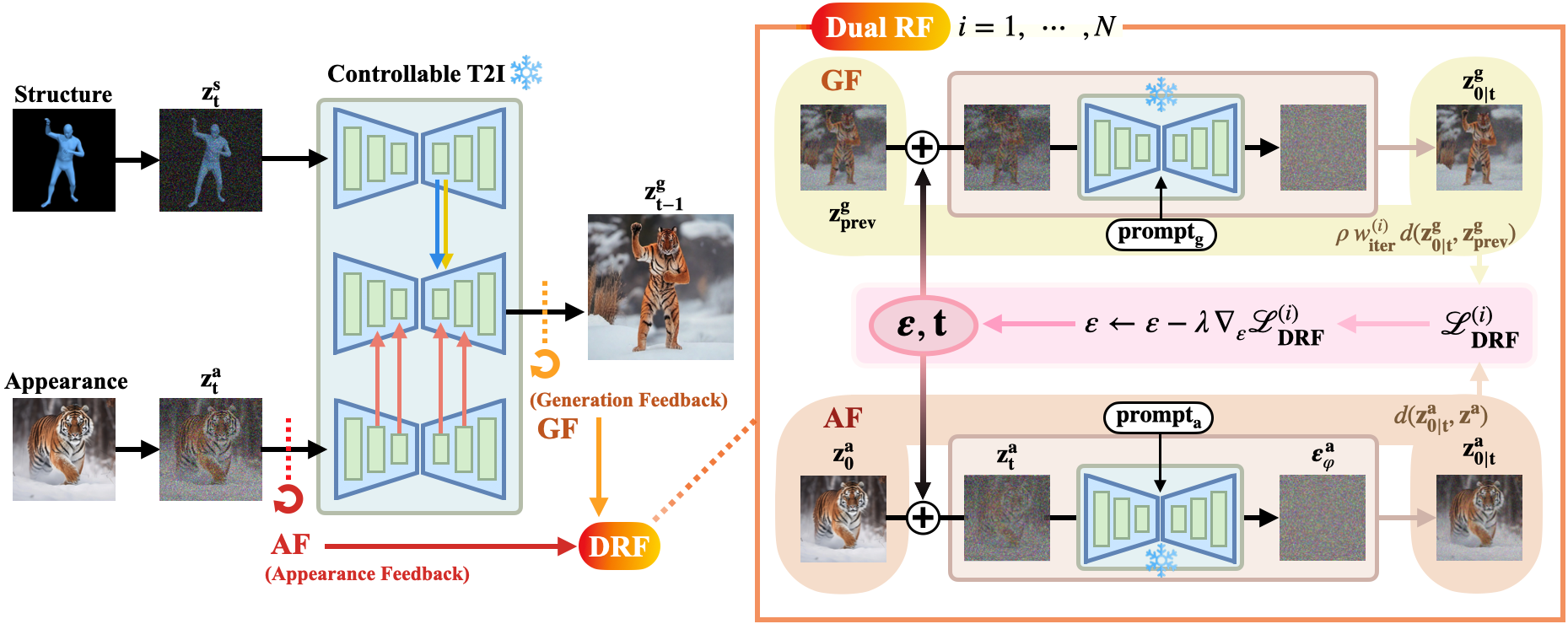
DRF iteratively updates by obtaining guided noises \(\epsilon_{\theta}^a\)
and \(\epsilon_{\theta}^g\) through appearance and generation feedback.
The distillation function derived from these two noises is combined to
update the generation latent.
Dual Recursive Feedback
Dual Recursive Feedback (DRF) couples the two feedback loops into a single training-free guidance rule. At each sampling step, we run the controllable T2I backbone with appearance and generation prompts to obtain guided noises \(\epsilon_{\theta}^a\) and \(\epsilon_{\theta}^g\), from which we form denoised latents \(z_{0|t}^a\) and \(z_{0|t}^g\). DRF defines an appearance reconstruction loss that pulls \(z_{0|t}^a\) toward the reference code \(z_0^a\), and a generation-consistency loss that keeps \(z_{0|t}^g\) close to the previous output \(z_{\mathrm{prev}}^g\), weighted by \(w_{\text{iter}}^{(i)}\). The gradient of this combined DRF loss is used to refine the shared noise update for \(z_t^g\), so that samples are recursively attracted to an identity-preserving, pose-consistent fixed point while remaining fully plug-and-play with the underlying diffusion sampler.

Dual Recursive Feedback. Appearance feedback pulls the
appearance latent toward an identity-preserving fixed point,
while generation feedback recursively aligns the fused latent with the
desired structure and text condition.
Conclusion
DRF is a training-free T2I diffusion framework that provides recursive feedback to each control component for effective control of appearance and structure. This feedback mechanism ensures that the final generation output aligns coherently with both the appearance image and the text-conditioned score, resulting in high-quality generated images. By employing a dual feedback strategy, DRF resolves the longstanding issues in prior T2I methods, the loss of appearance fidelity, and the inability to produce stable image generations across diverse datasets. Moreover, DRF exhibits robust performance in preserving structure and reflecting the intended appearance, as demonstrated in tasks such as pose transfer and image synthesis on class-invariant datasets. We further show that our approach can be seamlessly integrated into other T2I diffusion models, thereby offering a foundation for broader advancements in diffusion model sampling.
Citation
If you use this work or find it helpful, please consider citing:
@InProceedings{Kim_2025_ICCV,
author = {Kim, Jiwon and Kim, Pureum and Kim, SeonHwa and Park, Soobin and Cha, Eunju and Jin, Kyong Hwan},
title = {Dual Recursive Feedback on Generation and Appearance Latents for Pose-Robust Text-to-Image Diffusion},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {15491-15500}
}